cotalks.dev
Orgs
Login
SREcon21
2021
Videos
Prev
Page 1 / 4
Next
1 — SREcon21 - Spike Detection in Alert Correlation at LinkedIn
SREcon21
2 — SREcon21 - Trustworthy Graceful Degradation: Fault Tolerance across Service Boundaries
SREcon21
3 — SREcon21 - Games We Play to Improve Incident Response Effectiveness
SREcon21
4 — SREcon21 - Latency Distributions and Micro-Benchmarking to Identify and Characterize Kernel Hotspots
SREcon21
5 — SREcon21 - Food for Thought: What Restaurants Can Teach Us about Reliability
SREcon21
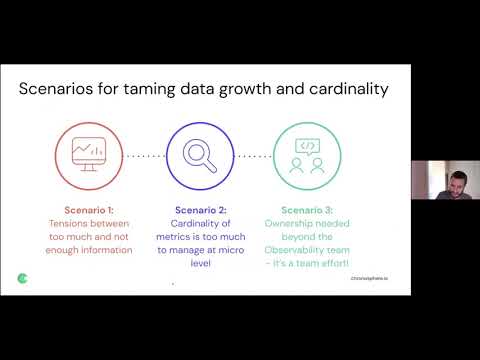
6 — SREcon21 - Taking Control of Metrics Growth and Cardinality: Tips for Maximizing Your Observability
SREcon21
7 — SREcon21 - Cache for Cash—Speeding Up Production with Kafka and MySQL binlog
SREcon21
8 — SREcon21 - A Retrospective: Five Years Later, Was Chaos Engineering Worth It?
SREcon21
9 — SREcon21 - The Origins of USAA's Postmortem of the Week
SREcon21
10 — SREcon21 - Beyond Goldilocks Reliability
SREcon21
11 — SREcon21 - Panel: Unsolved Problems in SRE
SREcon21
12 — SREcon21 - How Our SREs Safeguard Nanosecond Performance—at Scale—in an Environment Built to Fail
SREcon21
13 — SREcon21 - Experiments for SRE
SREcon21
14 — SREcon21 - SRE "Power Words"—the Lexicon of SRE as an Industry
SREcon21
15 — SREcon21 - Reliable Data Processing with Minimal Toil
SREcon21
16 — SREcon21 - Sparking Joy for Engineers with Observability
SREcon21
17 — SREcon21 - Hard Problems We Handle in Incidents but Aren't Recognized
SREcon21
18 — SREcon21 - Nine Questions to Build Great Infrastructure Automation Pipelines
SREcon21
19 — SREcon21 - Lessons Learned Using the Operator Pattern to Build a Kubernetes Platform
SREcon21
20 — SREcon21 - Improving Observability in Your Observability: Simple Tips for SREs
SREcon21